DeepSeek-R1:アーキテクチャとイノベーションの技術概要
DeepSeek-R1は、中国の新興企業DeepSeekの最新AIモデルで、生成AI技術の画期的な進歩を象徴しています。2025年1月にリリースされ、その革新的なアーキテクチャ、費用対効果、複数のドメインにわたる卓越したパフォーマンスで世界的な注目を集めている。
DeepSeek-R1の特徴
複雑な推論タスク、長いコンテキストの理解、およびドメイン固有の適応性を処理できるAIモデルに対する需要の高まりにより、従来の密な変換器ベースのモデルには限界があることが露呈しています。これらのモデルはしばしば次のような問題を抱えています:
推論中にすべてのパラメータをアクティブにすることによる高い計算コスト。
マルチドメインタスク処理における非効率性。
大規模展開に対するスケーラビリティの制限。
Core Architecture of DeepSeek-R1
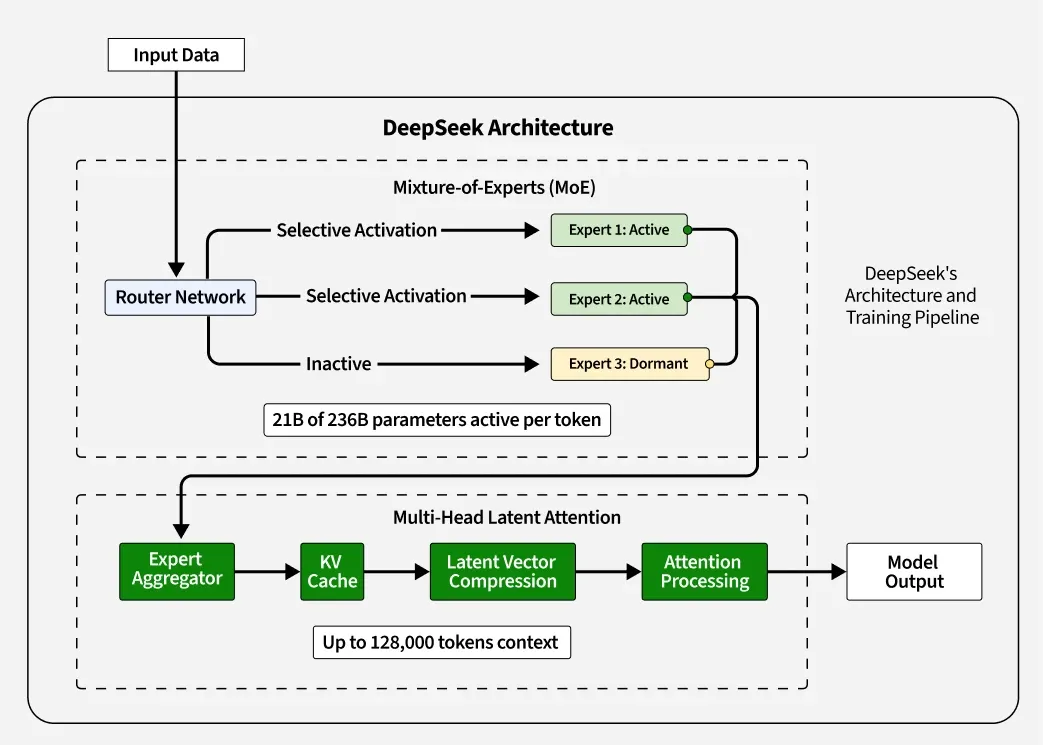
1. マルチヘッド潜在的注意(MLA)
MLA は、DeepSeek-R1 の重要なアーキテクチャの革新であり、DeepSeek-V2 で導入され、R1 でさらに改良されたもので、注意メカニズムを最適化し、推論中のメモリオーバーヘッ ドや計算の非効率性を削減するように設計されています。これはモデルのコア・アーキテクチャの一部として動作し、モデルがどのように処理し、出力を生成するかに直接影響します。
従来のマルチヘッドアテンションは、各ヘッドに対して別々のキー(K)、クエリ(Q)、バリュー(V)行列を計算する。
MLAはこれを低ランク因数分解アプローチに置き換えます。各ヘッドのK行列とV行列をキャッシュする代わりに、MLAはそれらを潜在ベクトルに圧縮します。
推論中、これらの潜在ベクトルは、各ヘッドのKV行列とV行列を再作成するためにオンザフライで解凍され、KVキャッシュサイズを従来の手法のわずか5~13%に激減させた。
さらに、MLAはロータリー位置埋め込み(RoPE)を設計に統合し、各QとKヘッドの一部を位置情報専用にすることで、ロングコンテクスト推論のような位置を意識したタスクとの互換性を維持しながら、ヘッド間での冗長な学習を回避している。
2. 専門家の混合(MoE): 効率性のバックボーン
MoEフレームワークは、与えられたタスクに対して最も関連性の高いサブネットワーク(または「エキスパート」)のみを動的に起動させ、効率的なリソース利用を保証するモデルである。このアーキテクチャは、これらのエキスパートネットワークに分散された6710億のパラメータで構成されています。
入力に基づいてどのエキスパートをアクティブにするかを決定する、統合されたダイナミック・ゲーティング・メカニズム。任意のクエリに対して、1回のフォワードパスで起動されるパラメータはわずか370億個であり、高いパフォーマンスを維持しながら計算オーバーヘッドを大幅に削減する。
このスパース性はLoad Balancing Lossのような技術によって達成され、ボトルネックを防ぐためにすべてのエキスパートが時間にわたって均等に利用されるようにする。
このアーキテクチャは、DeepSeek-V3(堅牢な汎用機能を備えた事前学習済みの基礎モデル)の基礎の上に構築され、推論能力とドメイン適応性を強化するためにさらに改良されています。
3. トランスフォーマーベースの設計
MoEに加えて、DeepSeek-R1には自然言語処理のための高度なトランスフォーマ層が組み込まれています。これらのレイヤーは、疎な注意メカニズムや効率的なトークン化のような最適化を組み込んで、テキスト内の文脈的な関係を捕捉し、優れた理解と応答生成を可能にします。
ハイブリッド注意メカニズムを組み合わせることで、注意の重み分布を動的に調整し、短い文脈と長い文脈の両方のシナリオでパフォーマンスを最適化します。
グローバルアテンションは、入力シーケンス全体の関係性を把握し、長い文脈の理解を必要とするタスクに最適です。
局所的注意は、文中の隣接する単語など、文脈上重要な小さなセグメントに焦点を当て、言語タスクの効率を向上させる。
入力処理を効率化するために、高度なトークン化技術が統合されています:
ソフトトークンマージ:重要な情報を保持しながら、処理中に冗長なトークンをマージします。これにより、変換レイヤーを通過するトークンの数が減り、計算効率が向上します。
ダイナミック・トークン・インフレーション:トークンのマージによる潜在的な情報損失に対抗するため、モデルはトークン・インフレーション・モジュールを使用し、後の処理段階で重要な詳細を復元します。
DeepSeek-R1モデルの学習方法
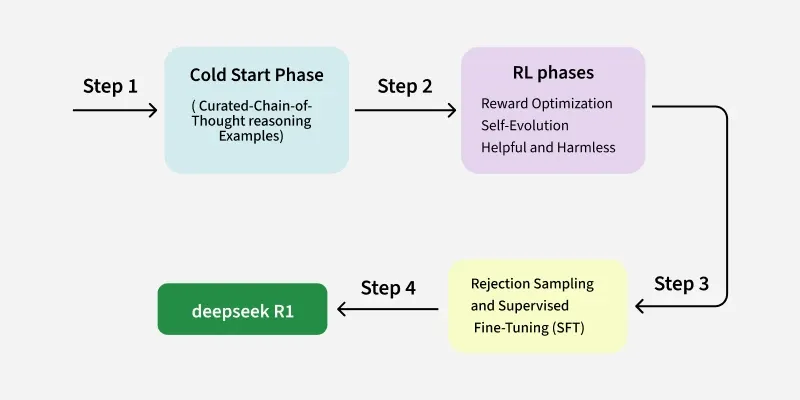
1. 最初の微調整 (コールドスタートフェーズ)
このプロセスは、慎重にキュレーションされた思考連鎖 (CoT) 推論例の小さなデータセットを使用して、ベースモデル (DeepSeek-V3) を微調整することから始まります。これらの例は、多様性、明瞭性、および論理的一貫性を確保するために慎重にキュレーションされます。
このフェーズが終了するまでに、モデルは推論能力の向上を示し、より高度なトレーニング・フェーズへの段階を設定します。
2. 強化学習(RL)フェーズ
最初の微調整の後、DeepSeek-R1 は複数の強化学習 (RL) 段階を経て、推論能力をさらに向上させ、人間の嗜好との整合性を確保します。
第1段階 報酬の最適化: 報酬モデルによって、正確さ、読みやすさ、フォーマットに基づいて出力にインセンティブが付与される。
ステージ2:自己進化: モデルが自律的に、自己検証(一貫性と正しさについて自身の出力をチェックする)、内省(推論プロセスにおけるエラーを特定し修正する)、エラー修正(反復的に出力を改良する)のような高度な推論行動を開発することを可能にする。
ステージ3:有用性と無害性の調整: モデルの出力が役に立ち、無害であり、人間の嗜好に沿ったものであることを確認する。
3. 拒絶サンプリングと教師あり微調整(SFT)
多数のサンプルを生成した後、拒絶サンプリングと報酬モデルにより、正確かつ読みやすい高品質な出力のみが選択される。このモデルはさらに、教師ありの微調整を使用して、この洗練されたデータセットで学習されます。教師ありの微調整には、推論に基づく質問だけでなく、より幅広い質問が含まれ、複数のドメインにわたる習熟度を高めます。
コスト効率: ゲームチェンジャー
DeepSeek-R1のトレーニングコストは約560万ドルで、高価なNvidia H100 GPUでトレーニングされた競合モデルよりも大幅に低い。コスト効率に貢献した主な要因は以下の通り:
MoEアーキテクチャによる計算要件の削減。
高価な代替GPUの代わりに2,000個のH800 GPUをトレーニングに使用したこと。
DeepSeek-R1は、AIアーキテクチャにおけるイノベーションの力を証明するものです。Mixture of Expertsフレームワークと強化学習技術を組み合わせることで、競合他社の数分の一のコストで最先端の結果を提供します。
